こんにちは、ByteDanceのtoB事業部BytePlusのセールスエンジニアリングリードの叶 長耀(ヨウ チョウヨウ)と申します。
今日はBytePlusはどんなものか、どういった製品やサービスを展開しているかについて書いてみたいと思います。
BytePlusとは
一言で言うと「ByteDance傘下のクラウドサービスです」。AmazonのAWSみたいな感じ。ByteDanceがDouyinを始め、たくさんのtoCアプリで培ってきた技術を企業様に提供します。
BytePlusのHQはシンガポール、インフラはシンガポールのDCになっています。製品ラインナップはレコメンド、エフェクト、動画編集、ビデオクラウド、CDN、SMS等PaaSとSaaSがメインになっています。今後IaaSやLLM関連のサービスも提供する予定です。
BytePlusの製品一覧
ウェイブサイトに全製品がリストされていますが、ここで簡単に各製品について説明します。
BytePlus レコメンド
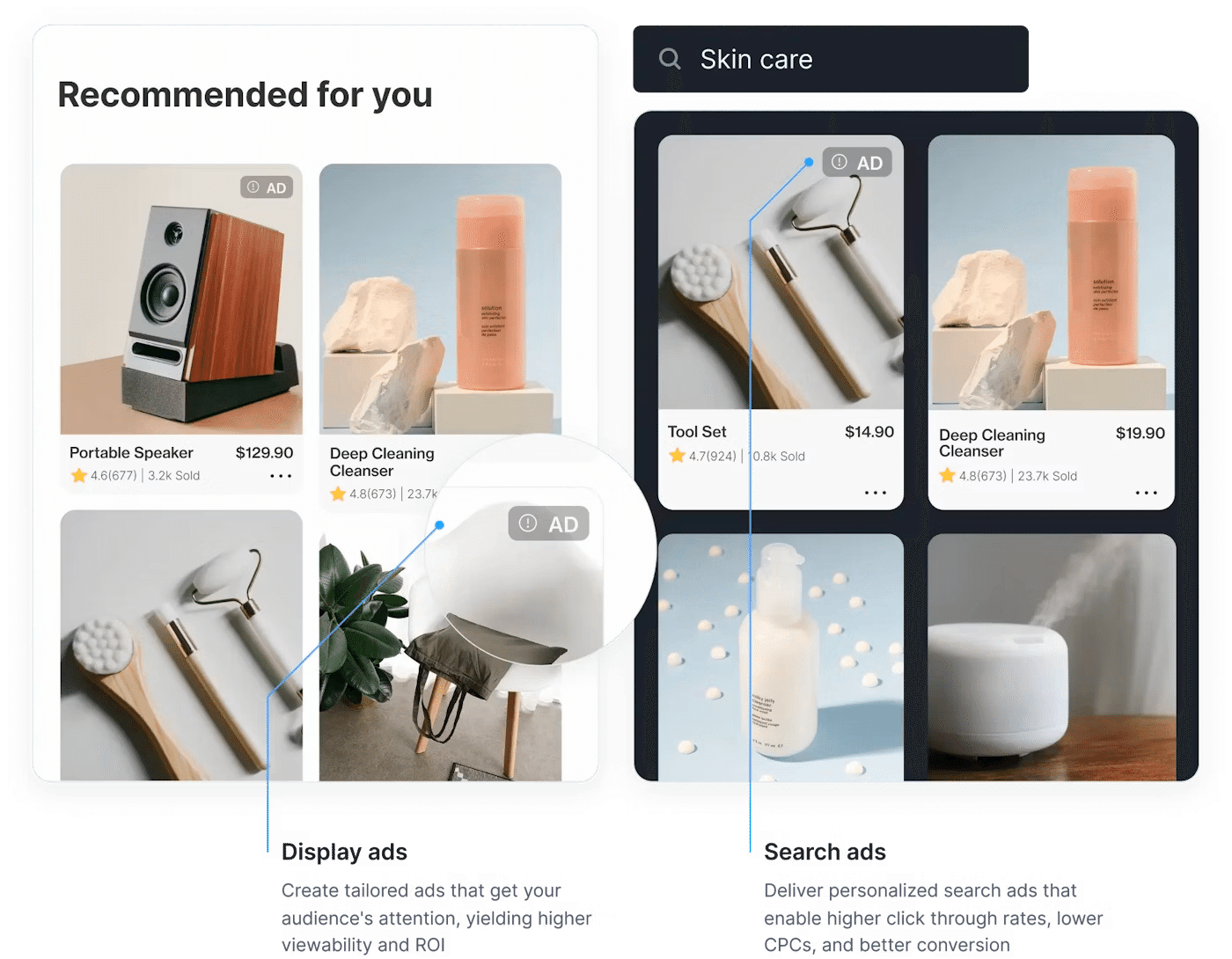
ECサイト、求人サイト、漫画、小説、ニュース、ライブ配信等コンテンツ数が多いサイト、アプリで使えるレコメンドエンジンです。特徴は3つあります。
リアルタイム性(リアルタイムでモデル自体の更新ができます)
コールドスタート(ユーザーとアイテム両方対応)
カスタマイズ性(柔軟なKPI設定、データスキーマ設計、BytePlusアルゴリズムエンジニアによるモデル作成とトレーニング、KPIに合わせた成果報酬課金等お客様のビジネスニーズに合わせて柔軟に対応可能です)
使われるデータは3つあります。
ユーザーの行動(一番重要。モデルへの寄与度は約80%)
コンテンツの属性データ(モデルへの寄与度は約15%)
ユーザーの属性データ(個人情報に触れない属性データ。モデルへの寄与度は約5%)
成果報酬課金モデルを採用される場合、PoCを実施します。BytePlusからアルゴリズムエンジニア1名+、ビッグデータエンジニア1名、データアナリスト1名、APIエンジニア1名、最小でも4人エンジニアがお客様ごとにアサインされます。
BytePlus Effects
SNS上でよく使われるエフェクトがありますよね。美白、美顔、Face Shaping、メイクアップ、2D/3Dステッカー、AR等様々な機能を企業様に提供できます。企業のサービスに組込むことでエンタメ要素を増やし、サービス全体の成長に貢献することができます。ライブ配信や動画作成、デーティングアプリ等によく使われます。

基本的にSDKの形で提供されます。一部API経由の呼び出しもあります。
CreativeStoreから確認することができます。
またデモアプリもございます。以下のQRコードをスキャンしダウンロードいただけます。

BytePlus Live/MediaLive
BytePlus LiveはライブストリーミングのSaaS製品です。主にライブコマース、社内大型イベント、オンライントレーニング等の用途に使われます。充実な機能、安定性、低遅延、安い等のメリットがあります。
https://assets.byteplus.com/obj/byteplus-assets/videos/live_product_highlights_3.mp4

コンソールから簡単にライブを作成、設定し、すぐにライブ配信ができます。
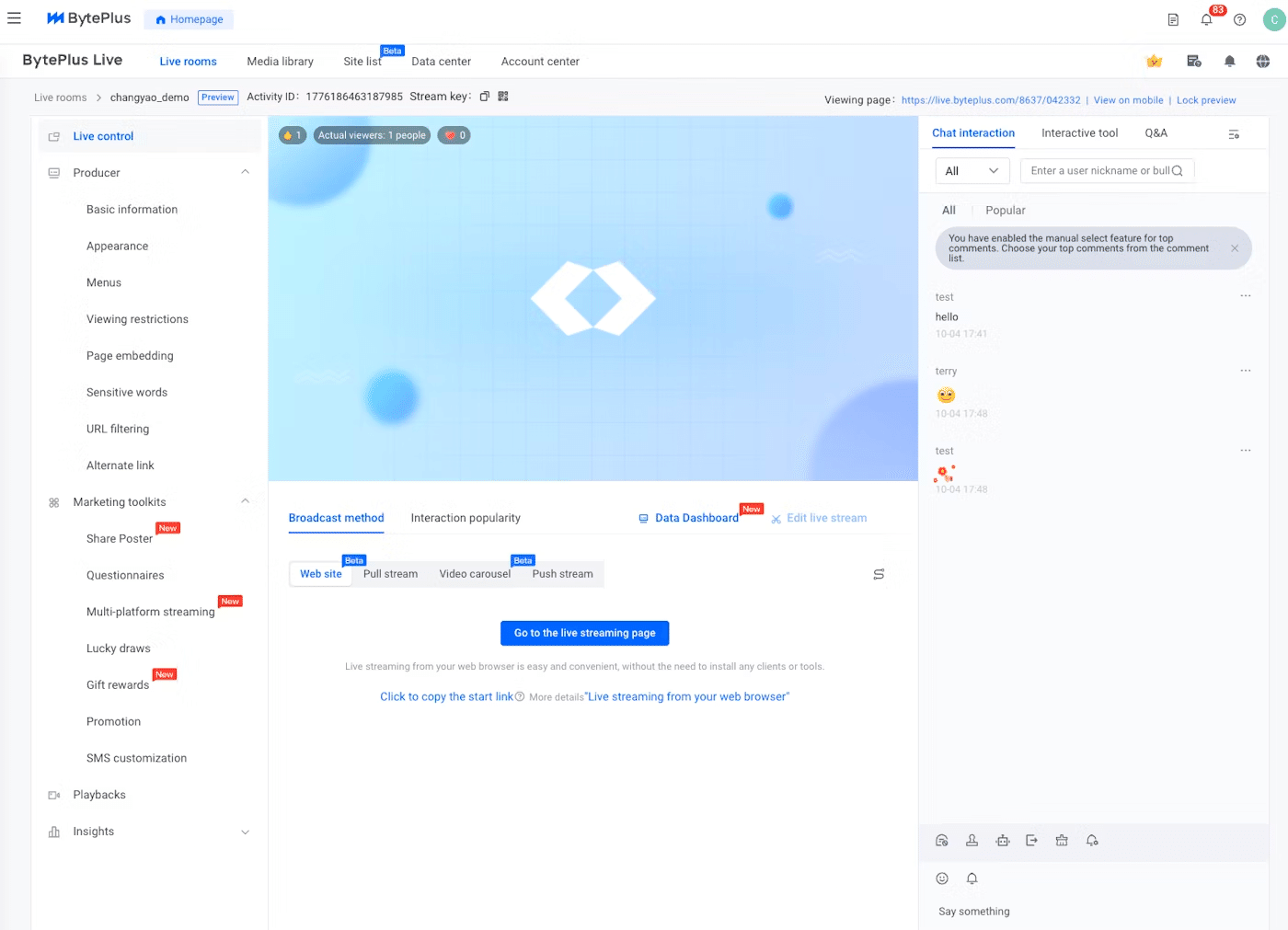
以下の画像はPC webページ視聴画面になります。簡単にお客様のウェブサイトに組込む(iFrameやWedSDK)ことができます。
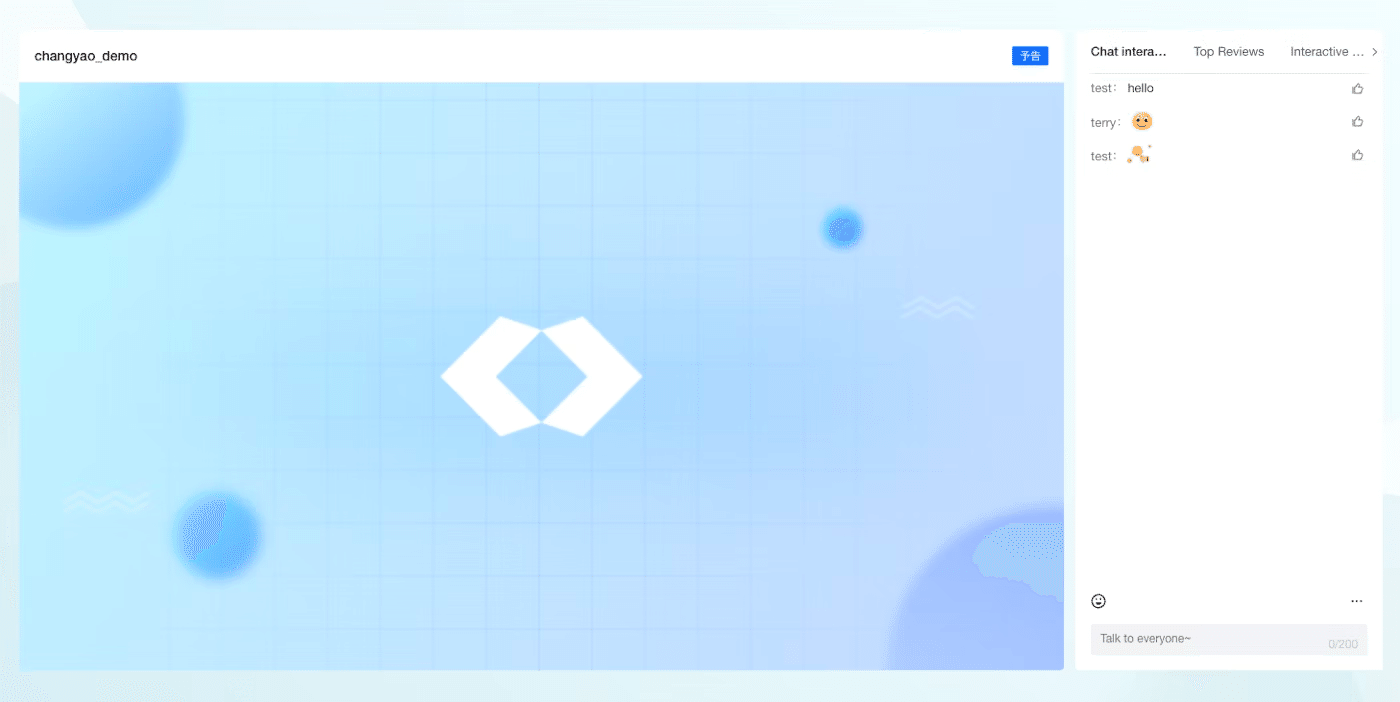
モバイルで開く場合は、以下のような感じです。
ブラウザ視聴ではなく、ネイティブアプリ中でもライブ配信や視聴ができます。Live Streaming SDKとViewer SDKが提供され、アプリ内に実装いただけます。
BytePlus MediaLiveはPaaSサービスになります。自由度がLiveより高く、様々なカスタマイズができます。
動画ライブ配信によく使われます。
BytePlus VoD
ビデオオンデマンド、エンドツーエンドの動画(ショート動画、ロング動画)サービスです(PaaS)。
以下の図は、メディアのアップロード、管理と処理(トランスコーディング等)、配信、再生など、BytePlus VODが提供するコア機能を示しています。
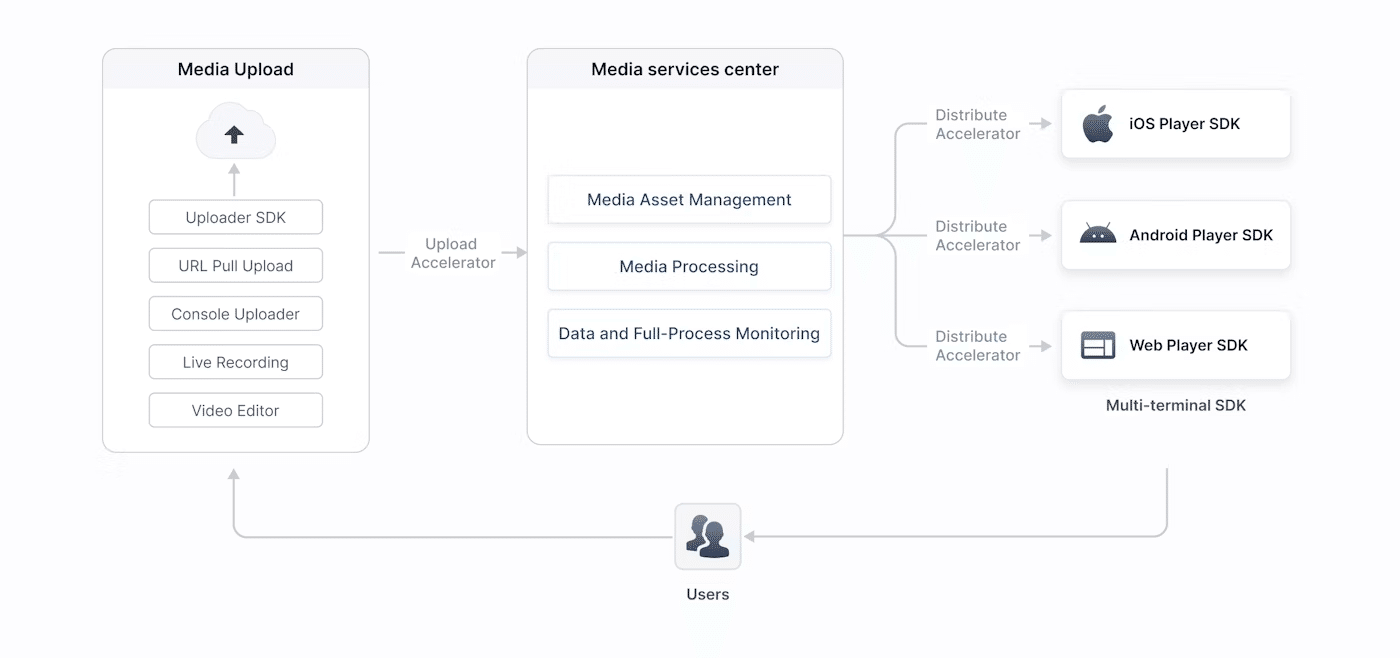
大規模なサービス上で実証されている低遅延、高品質、安定性の高いVoDサービス。
BytePlus VoD Playerをご利用いただけます。クラッシュ率0.001%以下、端末側で超解像によって画質を強化、ファーストフレーム表示が速いというメリットがあります。
ぜひ以下の動画を確認してみてください。違いがわかるかと思います。
https://assets.byteplus.com/obj/byteplus-assets/videos/vod_product_highlight_1.mp4
BytePlus RTC
Zoom等で使われるリアルタイムコミュニケーション技術です。ByteDanceのLark(Zoom, Slack, Google Workspace,メール等の合体)というツールでも使われています。
BytePlus RTCは高品質のリアルタイムオーディオとビデオのPaaSサービスです。

BytePlus RTCは他のサービス(VoD、Effect、MediaLive)と容易に連携できます。
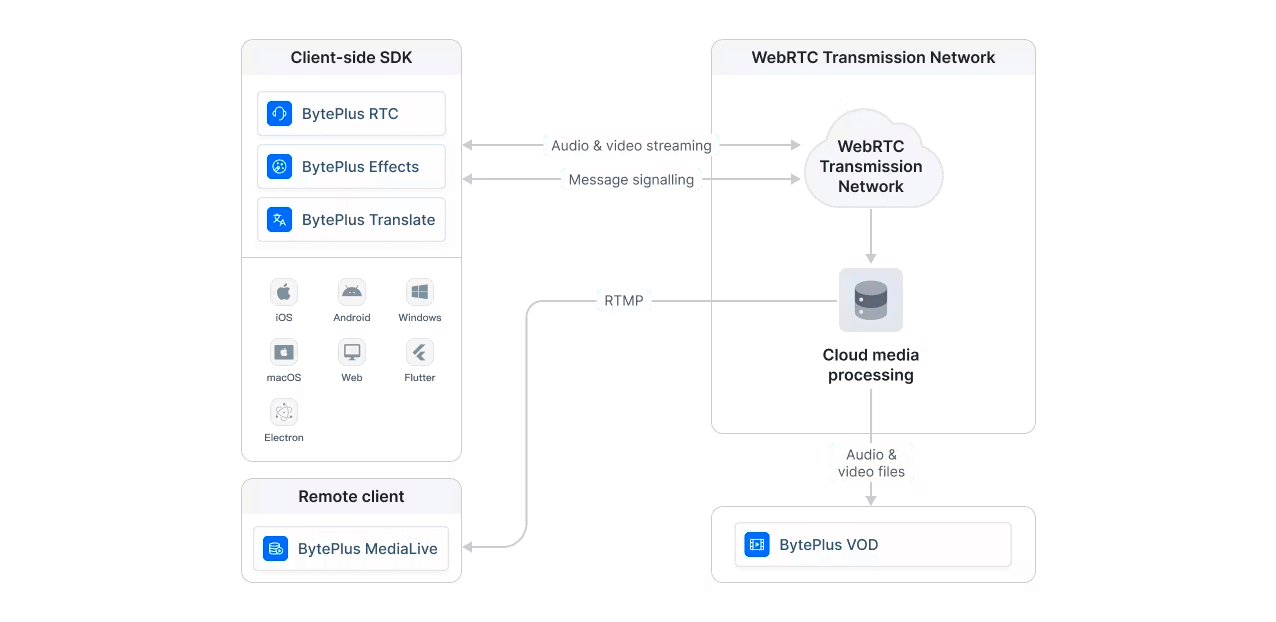
デモアプリはこちら
Web版:https://demo.byteplus.com/rtc/solution/videocall/login

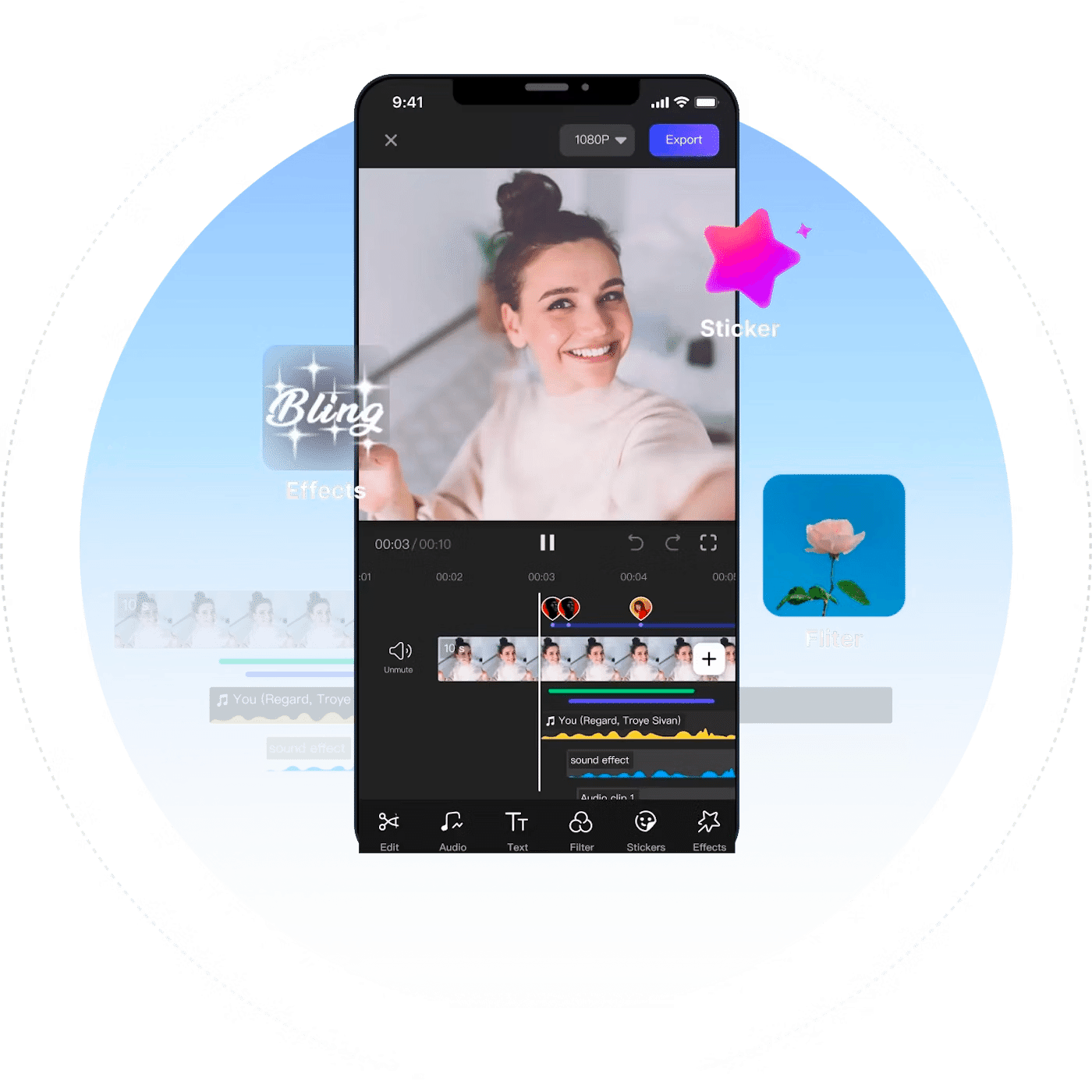
BytePlus Video Editor
BytePlus Video Editorは、ByteDanceのアプリ(抖音、CapCut、西瓜ビデオ、FaceU、Ulikeなど)で広く使われている動画編集技術です。UGCプラットフォームに必須と言っていいツールになります。
簡単に、短期間で質の高い動画を作ることができます。たくさんのSNS上の動画コンテンツがCapCutで作られていると言われています。
BytePlus AR
BytePlusは、顧客の様々なシナリオでARソリューションを提供しています。
BytePlusのAR技術には、Product AR, AR Try-on, SLAM, Landmark AR, Sky & Ground AR等がございます。ByteDanceのいろんなtoCアプリで利用され、業界で最も完成度の高いAIソリューションと言えます。
詳細の紹介はBytePlus AR Libraryをご参照ください。
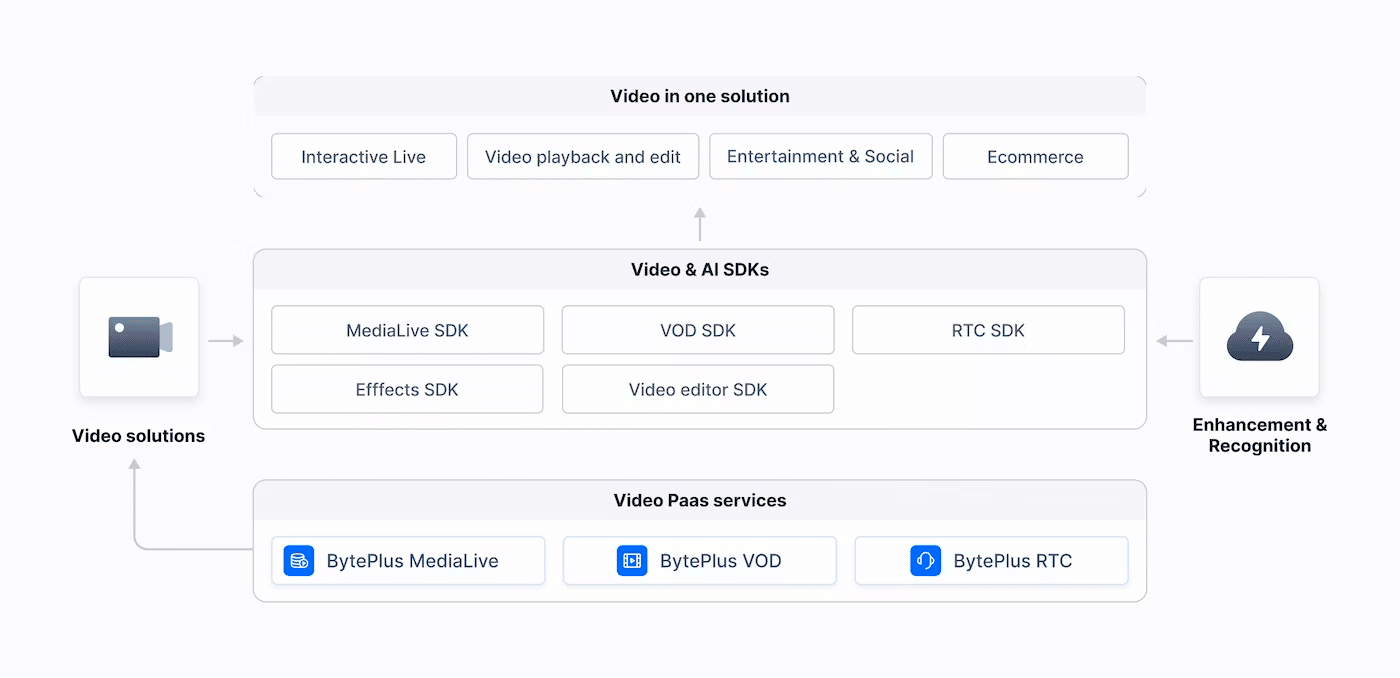
BytePlus VideoOne Solution
BytePlus VideoOneは今までご紹介した複数のビデオサービスを統合したソリューションになります。
MediaLive, VoD, RTCの他EffectsとVideo Editor機能も含まれており、そのものを実現できる強力なソリューションと言えます。
デモアプリもあります。
アプリストアで BytePlus VideoOneダウンロードしてみてください。
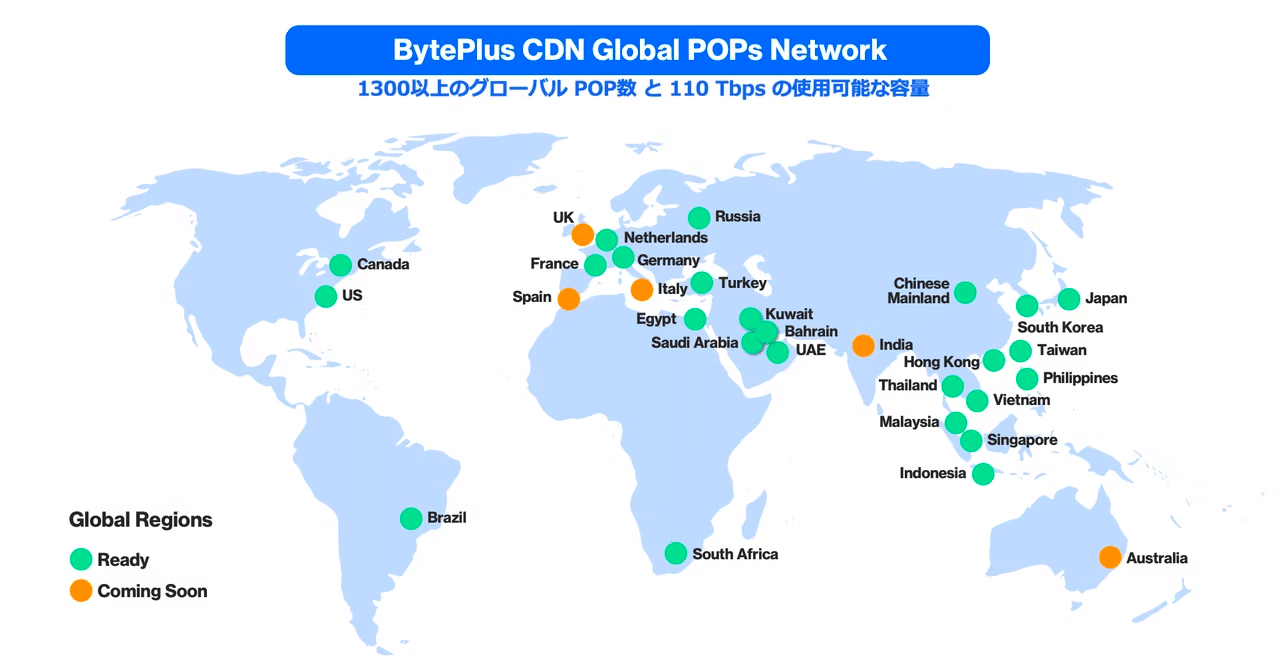
BytePlus CDN
CDNサービスも提供しております。
最新のHWとアーキテクチャを採用しており、低遅延、グローバルカバレッジ、コストパフォマンスが高いCDNになります。
BytePlus SMS
SMSサービスも全世界を展開しています。
本人認証用のワンタイムパスワードやマーケティングメッセージ等に使われます。
到達率が高く、コストパフォマンスが高い 等のメリットがあります。

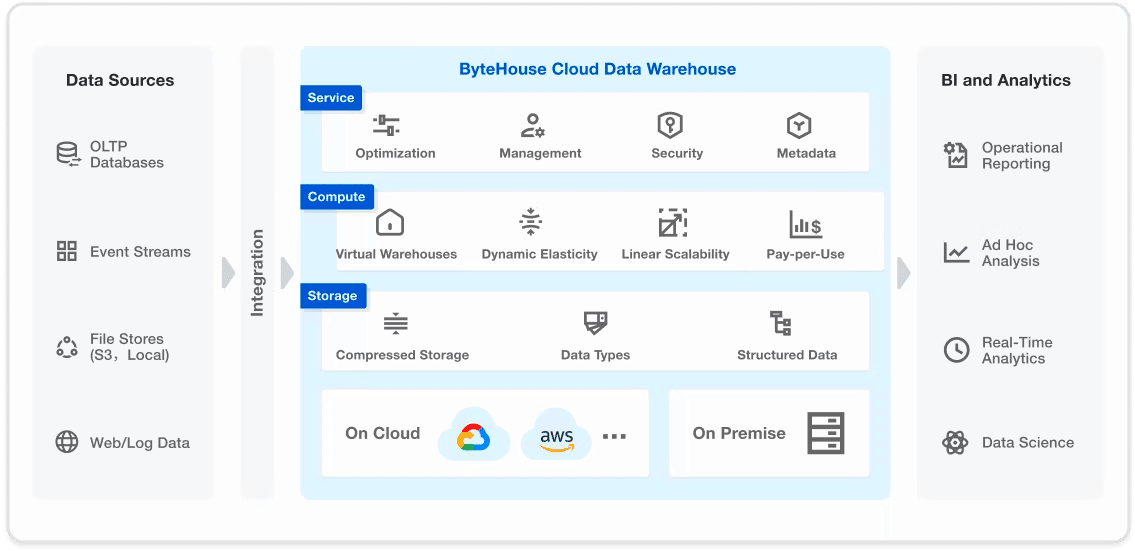
ByteHouse
クラウドネイティブのデータウェアハウスです。

最後
長くなりましたが、今後もいろんなサービスをリリースする予定です。
LLM、CapCut for Business等
ここまで読んでいただきありがとうございます。ぜひBytePlusを注目しておいてください。














